to do : 용어 정리 & 본문 정리
이 글을 쓰는 이유
램 선택의 기준은 물론 '필요하냐 필요하지 않냐'가 기준입니다.
그런데, 그 필요성을 따지는 것을 단순한 체감으로 판단하기는 쉽지 않습니다. 왜냐하면 사용자가 컴퓨터를 업그레이드를 하기도 전에 업그레이드 된 컴퓨터의 속도를 알 수 없기 때문이죠.
그래서 보통은 현재 컴퓨터 리소스(RAM, CPU 등)의 사용량을 확인합니다. 하지만 컴퓨터의 운영을 고려해보면 단순히 리소스의 사용량을 확인하는 것은 확실성을 떨어트릴 수 있습니다.
이 글에서는 업그레이드에 좀 더 확실한 근거를 제시하려고 합니다. 특히 램을 중점적으로 다뤄보겠습니다.
이 글은 추가적인 램이 필요한지에 대한 객관적인 기준을 다루는 것이 아닙니다. 어차피 물컵에 물이 반이 남아 있어도 '반이나 남았네!'라고 생각하는 사람도 있고, '반 밖에 안남았구나..ㅠㅠ' 라고 생각하는 사람도 있으니까요.
하지만 물컵도 보지 않고 '물은 충분히 남아있어!'라고 생각하지 않기를 바라는 마음에서 주관적인 평가를 내리기 위한 보다 객관적인 자료를 제시하는 겁니다.
가상메모리(Virtual Memory)
운영체제는 프로그램이 마음껏 메모리를 사용할 수 있도록 가상메모리를 할당합니다.
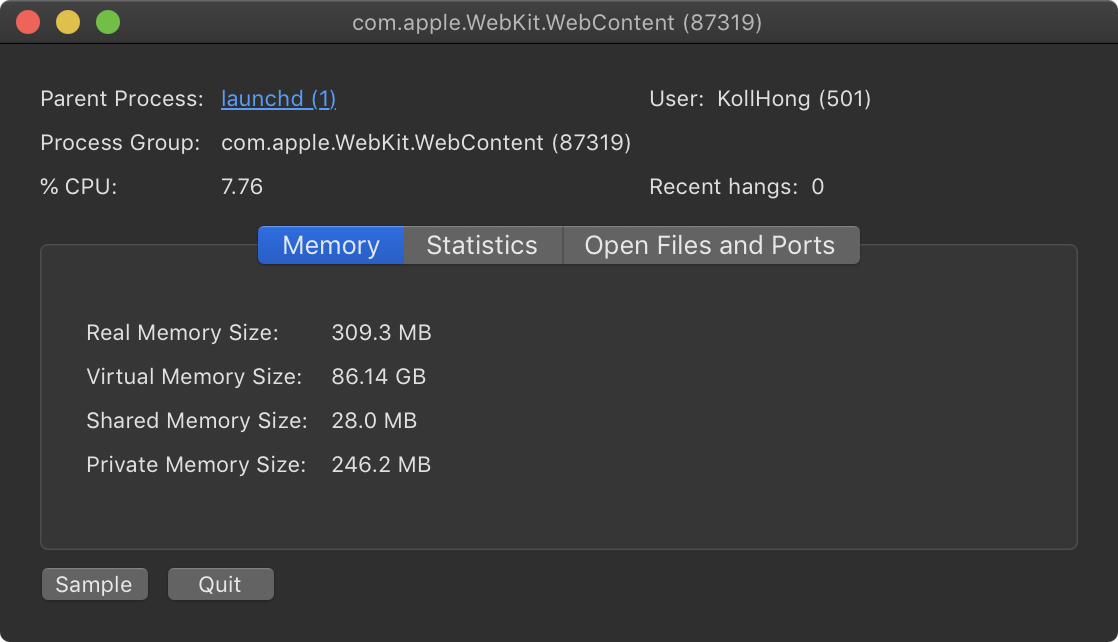
위 사진을 보면, 실제 사용량은 308MB이지만 운영체제에서 해당 프로세스에 할당한 가상 메모리는 86GB입니다. 저 크기의 데이터를 실제 메모리에 확보해두려고 한다면 당연히 시스템 운영이 불가능할 겁니다. 프로세스가 사용할 수 있는 메모리 공간(86GB)과 실제로 메모리를 점유하는 크기(308MB)는 다르다는 것이죠.
이것을 '가상메모리'라고 합니다. 가상 메모리 덕분에 (보조 기억장치의 공간이 충분하다면) OS는 해당 프로세스가 실제로 86GB 를 요구해도 문제 없이 실행되도록 하는 것이죠. 단, 예상하다시피 속도는 처참할 겁니다.
가상 메모리란, 각 프로그램에 실제 메모리 주소가 아닌 가상의 메모리 주소를 주는 방식을 말합니다(위키피디아). 애플리케이션이 '메모리의 한계를 계산하고 그에 따라 메모리 사용량을 줄이도록 하는 복잡한 코딩/연산과정'을 생략할 수 있도록 하는 기법입니다.
실제로 프로그래밍을 할 때에 변수를 만들면서 메모리의 남은 공간을 확인하고 변수를 만들지는 않습니다. 오히려 프로그래머들은 연산을 시작하기 전에 일단 변수 먼저 만듭니다. CPU의 연산 속도에 비해 램이 느리기 때문에 먼저 공간을 만들어두는 것이죠.
이런 식의 프로그램은 메모리 점유율이 커질 수밖에 없습니다. 그러나 메모리의 한계에 다다른다 하더라도 프로세스가 종료되거나 멈추지 않습니다.
이러한 방식은 멀티태스킹 운영 체제에서 흔히 사용되고, 실제 주기억장치보다 큰 메모리 영역을 제공하는 방법으로도 사용됩니다(위키피디아). OS는 애플리케이션에 메모리가 충분히 많다고 전달하고, 애플리케이션은 그 충분한 공간을 사용할 수 있게 됩니다. OS는 애플리케이션의 요구에 맞춰 메모리에 데이터를 저장합니다.
메모리 압축과 Swap (Paging)
그런데 만약 실제 메모리가 부족하다면 어떻게 할까요?
어차피 프로세스들은 OS를 통해 메모리에 접근하는 것이기 때문에 프로세스가 요구하는 메모리 데이터가 어디에 저장되든 상관 없습니다. 그 점을 이용해서 OS는 메모리 압축이나 Swap을 통해 공간을 확보합니다. 자주 사용하지 않을 것 같은 데이터는 압축하거나, 보조 기억 장치에 저장하는 거죠.
메모리가 부족하다는 것은 메모리 압축이나 Swap(스왑)이 발생할 때를 말합니다.
메모리 압축
압축은 딱히 설명할 게 없습니다. 메모리에서 자주 사용하지 않는 코드를 압축하는 거죠. 압축을 하면 50%넘게도 크기를 줄일 수 있습니다.
압축의 단점은 CPU 리소스를 사용한다는 것입니다. 컴퓨터의 모든 리소스 중 가장 빠른 리소스이지만, 컴퓨터의 성능에 가장 큰 영향을 미치는 리소스이기도 하죠.
압축한 데이터에 다시 접근해야 한다면 압축을 풀어야 합니다. OS가 사용자의 요구를 미리 예측할 수 없기 때문에 메모리에 접근하고자 할 때에 메모리 압축 해제를 하게 됩니다. 이 때 성능에 큰 영향을 끼치는거죠.
Swap (Paging)
스왑은 보조 기억장치를 주 기억장치처럼 활용하는 기법을 말합니다. 보조 기억장치는 CPU에 비하면 압도적으로 느립니다(다음 절에서 설명). 그렇기 때문에 스왑을 하더라도 일단은 압축을 해야 합니다. 그만큼 CPU 리소스를 사용할 수밖에 없습니다. 그리고, 발열 전력소비에도 영향을 끼치죠. 노트북의 경우는 발열이 늘면 성능 감소로도 이어집니다.
여기서도 메모리 압축과 같은 문제가 발생합니다. 압축하고 스왑한 데이터를 다시 사용하려면 보조 기억장치에서 주 기억장치에 불러와서 압축을 풀어야 합니다. 보조 기억장치의 기나긴 응답을 기다리고, 메모리에 로드 되면 성능에 가장 큰 영향을 미치는 CPU 리소스를 사용해 압축을 풀어야 합니다.
메모리 압축과 Swap의 결론
컴퓨터는 하드웨어 간의 속도 차이를 극복하기 같은 계층 구조를 사용합니다. CPU가 가장 빠르고, CPU 안에 있는 L1, L2, L3 캐시, 그 다음으로 주 기억장치, 보조 기억장치 순서입니다. 최고의 성능 발휘를 위해서 프로그래머나 OS, CPU 연구원들은 캐시를 활용하여 RAM에 엑세스하는 것을 최대한 줄여야 합니다. 사용자는 RAM이 부족해서 압축이나 Swap을 위해 보조 기억장치에 엑세스하는 것을 최대한 줄여야 합니다.
SSD도 느린가요?
만약 보조 기억장치의 리소스 사용량이 적고, 주 기억장치와 CPU의 리소스 사용량이 많은 연산을 한다면 압축은 하지 않고 Swap만 하는게 유리할 수도 있습니다. 하지만 보통은 그러지 않습니다. 보조 기억장치로 사용되는 SSD가 아무리 빨라졌다 하더라도 주 기억장치인 램에 비하면 굉장히 느립니다.
2018년 기준 최상급인 삼성 SSD 970 Pro나 Intel SSD 900P의 응답 속도가 70마이크로초~150마이크로초 수준입니다. 램은 2018년 기준 낮은 수준인 2133Mhz 메모리의 응답 속도가 50나노초 정도로, 마이크로초로 계산하면 0.05마이크로초가 됩니다. 1400배 빠른 응답 속도를 갖습니다. 이런 차이가 장기적으로 누적되면 큰 지연이 생기죠.
SSD보다도 1000배 이상 빠른 RAM도 연산 장치인 CPU에 비하면 굉장히 느립니다. 이런 속도 차를 극복하기 위해 CPU는 L1 캐시를 사용합니다. 최근에는 그 속도차이가 더 커져서 L2, L3, L4캐시도 등장했습니다.
Computer Action Avg latency 1초 정규화 3Ghz CPU Clock Cycle 0.3 ns 1s L1 Cache Access 0.9 ns 3s L2 Cache Access 2.8 ns 9s L3 Cache Access 12.9 ns 43s RAM Access 50ns 2.75 m NVMe SSD I/O 70 ~ 150 us 2h ~ 2 d Rotational disk I/O 1~10 ms 11d ~ 4 m
캐시
반대로 보조 기억장치가 느린 것을 보상하기 위해 메모리를 활용하는 기법이 있는데, 이를 캐시라고 합니다.

사진을 보면 Memory 열에서는 214MB, Real Memory 열에서는 309MB라고 나옵니다. 프로세스가 사용하는 메모리는 214MB인데, OS에서는 이 프로세스에 309MB를 사용합니다. OS가 자주 사용되는 코드, 그래서 추후 다시 사용 될 것 같은 코드를 미리 프로세스에 붙여두는거죠. 보조 기억장치가 너무 느리기 때문에 운영체제는 자주 사용되는 코드를 메모리에 보관하여 보조 기억장치에서 로드해야 할 코드를 메모리에서 찾는 겁니다.
OS의 가상메모리 운영
가상메모리에 신경써야 할 요소가 더 있습니다.
애플리케이션이 잘못 만들어진 것이 아니라면 갑자기 100GB이상의 메모리 데이터를 만들진 않을 겁니다. 하지만 1~2GB의 메모리 공간을 갑작스럽게 요구할 경우는 있겠죠. 그런데, 이 때 메모리가 부족하다면 어떻게 될까요?
운영체제는 애플리케이션이 메모리 공간을 추가로 요구할 때마다
- CPU 자원을 사용해서 자주 사용하지 않는 코드를 찾아내고
- CPU 자원을 사용하여 압축하고
- 보조 기억장치에 보관하는 동안 CPU 자원은 유휴 상태로 대기하고
- 보조 기억장치에 저장되면 메모리를 비우고 실행중인 애플리케이션에 할당
하는 작업을 반복 하는 걸까요?
만약 사실이라면 컴퓨터에서 애플리케이션을 실행하는 속도는 처참할 겁니다. OS는 애플리케이션이 어느 정도의 메모리 공간을 요구하는 것을 예측할 수 없기 때문에 애플리케이션이 1~2GGB의 공간이 필요하다 하더라도 실제로는 작은 크기의 데이터를 할당받는 것을 수백 번 반복하는 것입니다. 그 말은 자주 사용하지 않는 코드를 찾아 압축하는 작업을 수백번 반복하는 것이 됩니다.
개발자가 애플리케이션의 실행에 필요한 공간을 계산하여 미리 할당받는 방법도 있긴 하지만, 메모리 사용량을 예측할 수 없다면 필요할 때마다 추가로 요청해야 합니다. 그러라고 가상메모리라는 개념을 만든 것이기도 합니다.
게임으로 예를 들자면, 처음에 최대한 많은 데이터를 메모리에 로드해두는 방법도 있을겁니다. 하지만 대부분 게임은 라운드가 시작되거나 맵이 바뀔 때마다 다시 로딩을 합니다. 그런데 이렇게 애플리케이션이 실행되는 중에 로드하는 데이터들의 크기를 프로그래머가 예측하고 미리 할당받아두기는 쉽지 않습니다.
맵을 로드할때, 건물 개체와 그 개체에 그려질 그림(텍스처)를 로드해야 하는데, 미리 그 크기를 계산할 게 아니라면 건물 개체를 로드하고 다시 텍스처를 로드하는 방법을 사용해야 합니다. 게임 안에 건물이 몇개 나올까요? 엄청 많을겁니다.
그러므로 애플리케이션에서 수행하는 대용량의 메모리 공간 요청도 작은 크기의 메모리 할당을 여러번 반복하는 것이죠.
이러한 요청을 빠르게 수행하기 위해서는 1, 2, 3 단계를 건너뛸 방법이 필요합니다.
운영체제는 항상 어느 정도의 공간을 비워두도록 합니다. 덕분에 갑작스럽게 메모리를 요구할 때도 즉시 메모리를 할당하고 해당 애플리케이션이 다음 명령을 실행할 수 있습니다. 보통 OS는 10%~30%정도의 공간을 남겨둡니다.
주 기억장치가 8GB인 시스템에서는 2.5GB이하의 공간만 남아있다면 성능에 영향을 줄 정도로 압축이나 스왑이 된 것을 의심해야 합니다. 16GB의 시스템에서는 5GB이하의 공간만 남아있다면 성능에 영향을 줄 정도로 압축이나 스왑이 된 것을 의심해야 하는 겁니다.
본격적인 판단 기준
처음에도 언급했듯이, 주관적인 판단을 위한 객관적 지표인겁니다.
바로 윗 단에서 2.5GB 이하의 공간만 남아있다면 성능에 영향을 줄 정도라고 했습니다.
하지만 이 '성능'은 '체감 성능'이 아닙니다. '성능'만을 따진다면 메모리는 100GB로도 부족할겁니다. 캐시 기능이 덕분에 메모리는 많을수록 빨라집니다.
물론, 그 돈을 투자해서 CPU를 업그레이드 하는게 체감 성능은 더 좋아지겠죠. 이런 주관적인 판단을 위해 사용할 객관적 지표 '가상메모리'를 배웠습니다.
그러면 캐시는 없더라도, 압축이나 스왑이 없는 정도로 업그레이드 하면 될까요?
그것도 아닙니다. 압축이나 캐시가 있어도 됩니다. 아무리 시간에 민감한 사람이라도 '체감 성능' 기준으로 차이가 느껴지지 않을 수 있습니다.
1. 불필요한 데이터의 압축
메모리 압축은 자주 사용하지 않는 데이터를 대상으로 수행됩니다. 압축된 메모리를 사용할 때는 다시 압축을 해제해야 하기 때문에, 자주 사용하는 데이터에 적용하지는 않을겁니다.
그 중에서도 정말로 사용하지 않는 코드인 경우에는 압축되거나 Swap되어도 성능에 영향이 없습니다. 프로세스가 통채로 압축되는게 아니고 프로세스의 일부만 압축할 수도 있습니다. 그래서 모든 프로세스를 골고루 사용중이라도 그 중 일부 기능은 자주 사용하지 않는다면 압축되어도 체감 차이는 없을 수 있습니다.
2. 부속 장치를 기다림
다른 장치를 기다려야 하는 애플리케이션이라면 체감되지 않을 수 있습니다다.
HDD 불량 확인 프로그램으로 HDD를 검사한다고 가정합시다. 이 컴퓨터의 메모리가 부족하여 Swap 되더라도 컴퓨터는 하드디스크의 불량 확인 속도에 체감하는 차이가 없을 것입니다.
여기서 생기는 가장 큰 지연은 HDD의 지연이기 때문입니다. CPU나 램은 Swap 때문에 연산량이 늘어났지만, 어차피 HDD를 기다려야 하는 시간 때문에 유휴 시간이 더 깁니다.
간단히 커서를 움직이는 동작을 비교해봅시다. 한 컴퓨터는 1Ghz 듀얼코어 컴퓨터이고, 한 컴퓨터는 4Ghz 옥타코어입니다. 그 외 스펙은 모두 같습니다. 아무것도 없는 바탕화면에 커서만 움직이는데 체감 차이가 느껴질까요? 아닙니다. 분명 같은 연산을 수십배 이상 느린 컴퓨터에서 수행하는건데 왜 체감 차이가 없을까요?
그 이유는 이 상황에서는 모니터의 지연이 원인이기 때문입니다. 보통의 60Hz모니터는 약 16ms의 지연을 가집니다. 1Ghz 듀얼코어 시스템이라 하더라도 마우스를 움직이는데 16ms까지 필요하지는 않은게 그 이유입니다..
메모리 확인 방법
위에서 알아본 이론적인 구조를 직접 확인할 수 있어야 메모리 업글레이드가 필요한지 알 수 있습니다.
보조 기억장치는 느립니다. 그렇기 때문에 보조기억장치를 사용하는 Swap은 최후의 단계라고 보면 됩니다. 개인적으로는 Swap 크기가 2GB이상일 경우는 누구라도 속도 차이를 느낄 수 있다고 생각합니다. 메모리 압축은 5GB 이상이라면 누구라도 속도 차이를 느낄 수 있을 것이라고 생각합니다.(16GB램 기준)
여기서 함께 확인해야 할 것은 자신의 사용 환경과 가격 부분을 고려해야 합니다. 만약에 백그라운드형 프로그램이 굉장히 많고, 이 프로그램들이 반복적인 코드만을 수행한다면 스왑이나 압축이 굉장히 커도 큰 차이는 없을 겁니다. 필요 없는 부분만 압축했기 때문이죠. 또한 체감 차이가 생긴다 하더라도 메모리 가격 대비 유익한 체감차이인지도 생각해봐야 하고요.
맥OS(MacOS)
맥은 메모리가 항상 캐시로 가득 차 있습니다. 어느 정도 사용하고 나면 여유 메모리는 300MB미만이 됩니다.
또한 맥은 Swap을 하는 한이 있어도 일단은 캐시는 어느 정도 남겨둡니다. iOS도 같습니다.
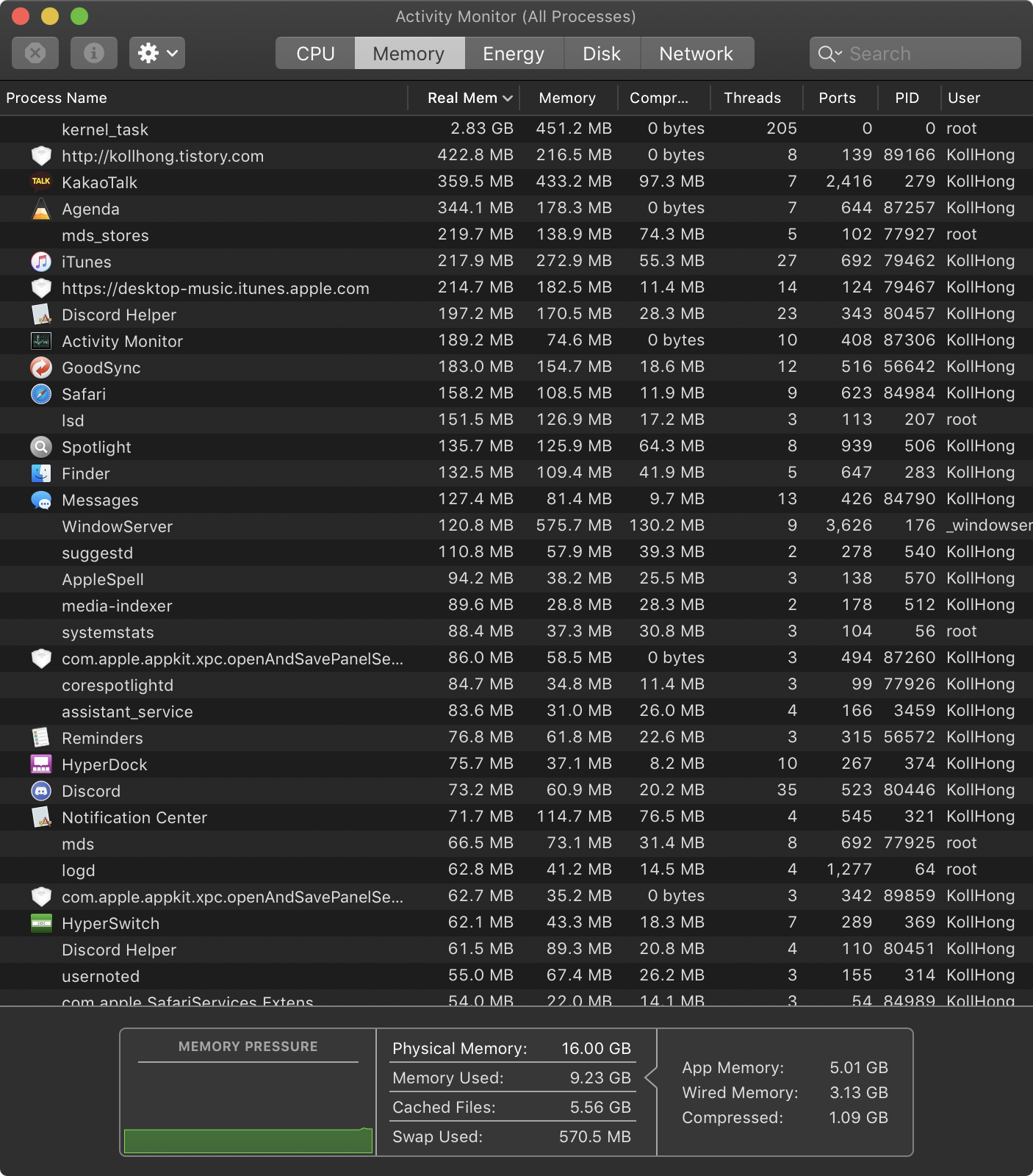
활성 상태 보기(Activity Monitor) 앱을 실행합니다. 그리고 메모리 탭을 클릭하면 위와 같이 나옵니다.
아래쪽에 Swap Used와 Compressed를 통해 전체적인 압축량과 스왑 사용량을 확인할 수 있습니다. 맥은 활성 상태 보기에서 앱별 압축된 양도 확인할 수 있습니다.
메뉴바에서 '보기 -> 열 -> 실제 메모리, 압축 된 메모리'를 체크하면 됩니다. 여기서 각 프로세스별로 압축된 양을 보고 시스템 업그레이드가 필요할지 주관적으로 판단하면 됩니다.
맥의 경우는 Hibernate를 할 때에 메모리의 데이터를 최대한 압축하고 스왑한 후에 컴퓨터를 끕니다. 덕분에 16GB 메모리를 사용 중이라도 Hibernate 파일은 3GB를 넘지 않죠. 그런데 시스템이 복원 된 후에도 다시 사용하지 않는 코드는 메모리가 여유롭다 하더라도 스왑 상태로 남습니다. 이를 속도가 저하되는 요인이고, 메모리 업그레이드 후에 체감 차이가 생긴다고 여기면 안됩니다.
주 : Hibernate : 메모리의 데이터를 보조기억장치에 저장하고 컴퓨터를 끕니다. 컴퓨터를 켜면 이 데이터를 복원하고 잠자기(Sleep)에서 깨어난 것처럼 작동합니다.
윈도우(Windows)
윈도우즈가 올바른 외래어 표기입니다. 하지만 한국 MS가 윈도우라고 표기합니다. 고유명사가 표기법보다 우선이니 '윈도우'라고 해야 합니다.
윈도우는 작업 관리자에서 성능 탭을 보면 됩니다.
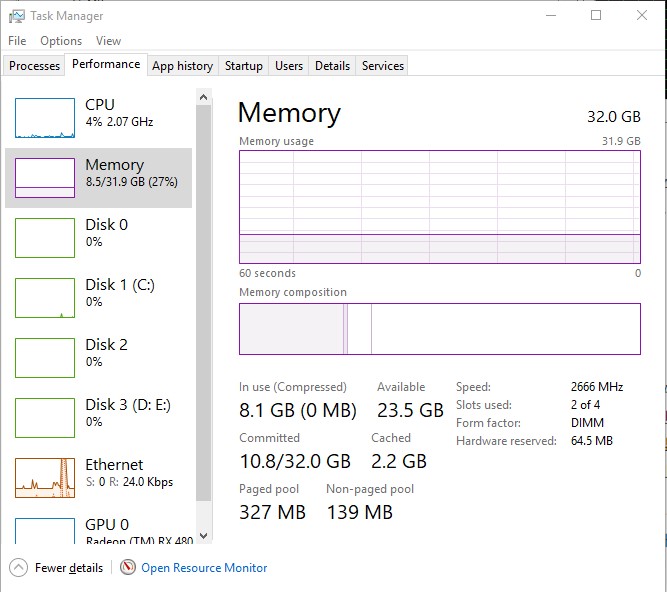
Swap을 윈도우에서는 페이징(Paging)이라고 합니다. 윈도우의 경우 페이징은 정확한 수치로 나오지 않습니다. 여기서 확인해야 할 것은 Committed(커밋 됨)과 In use(사용 중), 그리고 Compressed(압축 됨)입니다. Commit은 OS에서 메모리를 할당한 부분입니다. 캐시를 포함하여 압축, 페이징 크기도 Committed에 포함됩니다..
'In use(사용 중)' + 'Available(사용 가능)' = 사용 가능한 RAM 크기
: 캐시나, 페이징에 대한 부분은 계산에서 제외됩니다. 그래서 실제 메모리 사용량과는 다릅니다.'Committed(커밋 됨)' = 주소를 가진 데이터의 크기
: 압축 된 데이터나 페이징 된 데이터는 압축 이전의 크기로 표시될 수 있습니다.
'In use(사용 중)', 'Paged pool(페이징 풀)*', 'Non-paged pool(비 페이징 풀)**', 'Paging***' 등을 포함합니다.
'Cached(캐시 됨)'은 'Committed(커밋 됨)'에 포함되지 않습니다.
*페이징 풀은 RAM에 있는 커널 개체에 대한 가상 주소를 보관합니다.
**비 페이징 풀은 RAM 외의 장치에서 가져올 수 있는 데이터에 대한 가상 주소를 보관합니다.
***페이징 파일이 있을 경우에는 Committed(커밋 됨) 항목의 분모가 전체 메모리 크기보다 큽니다(커질 가능성이 높다).
CPU가 보조 저장장치에 비해 압도적으로 빠르기 때문에 페이징을 할 때도 압축을 거친 후에 보조 저장장치에 저장합니다.
그런데 윈도우에서는 실제 페이징 크기나 압축 크기가 아닌, 압축 이전의 크기만 나옵니다. 그래서 압축 전의 데이터 크기와 페이징 이전의 크기를 가지고 주관적으로 판단해야 합니다.
하지만 윈도는 또 다른 객관적 자료를 제공합니다.
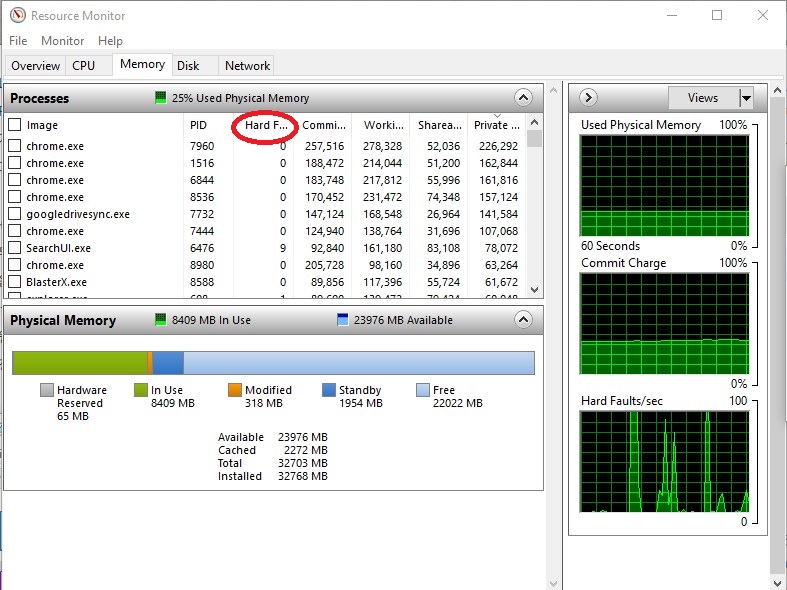
Resource Monitor(리소스 모니터)의 메모리 탭에서 Hard Faults(하드 폴트)를 확인할 수 있습니다.
이 열은 프로세스가 초당 하드 페이지 폴트 요청 횟수의 1분 동안의 평균치를 보여줍니다. 자주 사용하는 프로그램이 하드 폴트가 많으면 메모리를 늘릴 필요가 있는겁니다.
MacOS에서는 페이지 폴트를 서드파티(3rd Parties) 프로그램을 이용하면 확인할 수 있습니다.
마치며…
처음부터 강조한 것인데, 개인의 선택에 달린겁니다. 하지만 단순히 OS가 표시하는 RAM의 사용량만 보는 것은 선택에 대한 근거로는 부족하죠.
그래서 OS가 메모리를 관리하는 방법을 알아보고 메모리가 얼마나 사용되고 있는지 더 정확하게 추정한 후에 주관적으로 결정해야 합니다. 사용자의 컴퓨터가 사용자가 하고자 하는 작업에 사용자가 요구하는 성능을 보여줄 수 있는지 생각해봐야 합니다.
OS는 상당히 복잡하여 현재의 구성에서 각종 프로세스와 하드웨어를 조절하여 각종 요소의 균형을 유지할 수 있도록 동적으로 관리합니다. 때문에 단순히 컴퓨터의 리소스 사용량만을 보고 판단하기 어렵죠.
이는 RAM 뿐 아니라 다른 장치들도 마찬가지입니다. CPU는 캐시의 속도에 따라서도 성능 차이가 생기고, 디코더의 속도에 따라서도 성능 차이가 생깁니다. 그래서 CPU사용량이 30%정도라 해도 업그레이드를 하면 성능 차이가 느껴질 수 있죠. 캐시 또한 성능에 영향을 미치는 요소이지만 작업 관리자에 나타나지 않습니다.
SSD도 마찬가지입니다. 단순히 읽기 속도가 빠른 것만이 장점인 것은 아닙니다. SSD는 읽기/쓰기 요청에 대해 응답속도가 굉장히 빠른 것이 장점입니다. 이 장점을 살리는 인터페이스가 NVMe구요. 초당 IO 처리 횟수를 의미하는 IOPS는 단순한 파일 복사로는 판단할 수 없습니다. 작은 크기의 파일을 여러 개 복사해야 IO요청이 여러개 생기기 때문이죠. 이건 벤치마킹 소프트웨어를 통해 판단할 수 있습니다. GPU와 HDD에 대해서도 단순히 사용량만 확인할 것이 아니라 좀 더 다양한 기준을 찾아 평가할 필요가 있습니다.